모든 글은 다음 블로그를 참고하여 작성하였습니다.
https://gyoogle.dev/blog/
Linked List
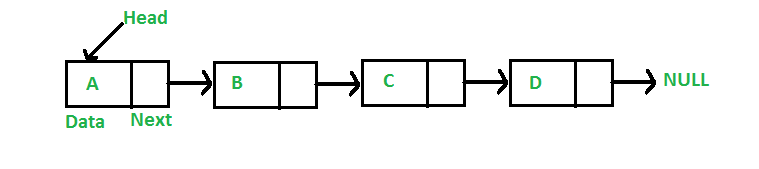
연속적인 메모리 위치에 저장되지 않는 선형 데이터 구조
왜 Linked List를 사용하나?
- 기존 배열의 단점 배열은 비슷한 유형의 선형 데이터를 저장하는데 사용할 수 있지만 제한 사항이 있음
-
배열의 크기가 고정되어 있어 미리 요소의 수에 대해 할당을 받아야 함
-
새로운 요소를 삽입하는 것은 비용이 많이 듬 (공간을 만들고, 기존 요소 전부 이동)
- 장점
- 동적 크기
- 삽입/삭제 용이
- 단점
- 임의로 액세스를 허용할 수 없음. 즉, 첫 번째 노드부터 순차적으로 요소에 액세스 해야함 (이진 검색 수행 불가능)
- 포인터의 여분의 메모리 공간이 목록의 각 요소에 필요
Array vs ArrayList vs LinkedList


- Array는 index로 빠르게 값을 찾는 것이 가능함
- LinkedList는 데이터의 삽입 및 삭제가 빠름
- ArrayList는 데이터를 찾는데 빠르지만, 삽입 및 삭제가 느림
스택 & 큐
동적 배열 스택
- 기존의 방법대로 구현하면 스택에는 MAX_SIZE라는 최대 크기가 존재해야 한다
- 최대 크기가 없는 스택을 만드려면?
arraycopy를 활용한 동적배열 사용
기존 스택의 2배 크기만큼 임시 배열(arr)을 만들고
arraycopy를 통해 stack의 인덱스 0부터 MAX_SIZE만큼을 arr 배열의 0번째부터 복사한다
복사 후에 arr의 참조값을 stack에 덮어씌운다
마지막으로 MAX_SIZE의 값을 2배로 증가시켜주면 된다.
이러면, 스택이 가득찼을 때 자동으로 확장되는 스택을 구현할 수 있음
(연결리스트로도 구현 가능)
원형 큐
- 일반 큐의 단점 : 큐에 빈 메모리가 남아 있어도, 꽉 차있는것으로 판단할 수도 있음 (rear가 끝에 도달했을 때)
- 이를 개선한 것이 ‘원형 큐’. 논리적으로 배열의 처음과 끝이 연결되어 있는 것으로 간주함!
연결리스트 큐
-
원형 큐의 단점 : 메모리 공간은 잘 활용하지만, 배열로 구현되어 있기 때문에 큐의 크기가 제한
-
이를 개선한 것이 ‘연결리스트 큐’. 연결리스트 큐는 크기가 제한이 없고 삽입, 삭제가 편리
힙
우선순위 큐를 위해 만들어진 자료구조
- 우선순위 큐 : 우선순위의 개념을 큐에 도입한 자료구조. 시뮬레이션 시스템, 작업 스케줄링, 수치해석 계산에 사용
- 삽입 : O(logn) , 삭제 : O(logn)
- 힙 트리는 중복된 값 허용 (이진 탐색 트리는 중복값 허용X)
힙 종류
-
최대 힙(max heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
-
최소 힙(min heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리

힙의 삽입
-
힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 삽입
-
새로운 노드를 부모 노드들과 교환
힙의 삭제
-
최대 힙에서 최대값은 루트 노드이므로 루트 노드가 삭제됨 (최대 힙에서 삭제 연산은 최대값 요소를 삭제하는 것)
-
삭제된 루트 노드에는 힙의 마지막 노드를 가져옴
-
힙을 재구성
이진탐색트리 (Binary Search Tree)
- 이진 탐색의 효율적인 탐색 능력 + 연결리스트의 삽입 삭제
특징
- 각 노드의 자식이 2개 이하
- 각 노드의 왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 큼 (왼<부모<오)
- 중복된 노드가 없어야 함
중복이 없어야하는 이유는?
-
검색 목적 자료구조인데, 굳이 중복이 많은 경우에 트리를 사용하여 검색 속도를 느리게 할 필요가 없음. (트리에 삽입하는 것보다, 노드에 count 값을 가지게 하여 처리하는 것이 훨씬 효율적)
-
이진탐색트리의 순회는 ‘중위순회(inorder)’ 방식 (왼쪽 - 루트 - 오른쪽)
-
중위 순회로 정렬된 순서를 읽을 수 있음
BST 핵심연산
- 검색
- 삽입
- 삭제
- 트리 생성
- 트리 삭제
시간 복잡도
- 균등 트리 : 노드 개수가 N개일 때 O(logN)
- 편향 트리 : 노드 개수가 N개일 때 O(N)
삽입, 검색, 삭제 시간복잡도는 트리의 Depth에 비례
삭제의 3가지 Case
-
자식이 없는 leaf 노드일 때 → 그냥 삭제
-
자식이 1개인 노드일 때 → 지워진 노드에 자식을 올리기
-
자식이 2개인 노드일 때 → 오른쪽 자식 노드에서 가장 작은 값 or 왼쪽 자식 노드에서 가장 큰 값 올리기
해시 (Hash)
데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.
1 | |
결국 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌나는 현상이 발생함 ‘collision’ 현상
- 그래도 해시 테이블을 쓰는 이유는?
적은 자원으로 많은 데이터를 효율적으로 관리하기 위해
하드디스크나, 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해짐!
- 언제나 동일한 해시값 리턴, index를 알면 빠른 데이터 검색이 가능해짐
- 해시테이블의 시간복잡도 O(1) (이진탐색트리는 O(logN))
충돌 문제 해결
-
체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식 (제한 없이 계속 연결 가능, but 메모리 문제)
-
Open Addressing : 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장할 수 있도록 허용 (해당 키 값에 저장되어있으면 다음 주소에 저장)
-
선형 탐사 : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함
-
제곱 탐사 : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함
트라이
문자열에서 검색을 빠르게 도와주는 자료구조
1 | |
1 | |
B Tree & B+ Tree
- 이진 트리는 하나의 부모가 두 개의 자식밖에 가지질 못하고, 균형이 맞지 않으면 검색 효율이 선형검색 급으로 떨어진다. 하지만 이진 트리 구조의 간결함과 균형만 맞다면 검색, 삽입, 삭제 모두 O(logN)의 성능을 보이는 장점이 있기 때문에 계속 개선시키기 위한 노력이 이루어지고 있다.
B Tree
데이터베이스, 파일 시스템에서 널리 사용되는 트리 자료구조의 일종이다.
이진 트리를 확장해서, 더 많은 수의 자식을 가질 수 있게 일반화 시킨 것이 B-Tree
자식 수에 대한 일반화를 진행하면서, 하나의 레벨에 더 저장되는 것 뿐만 아니라 트리의 균형을 자동으로 맞춰주는 로직까지 갖추었다. 단순하고 효율적이며, 레벨로만 따지면 완전히 균형을 맞춘 트리다.
1 | |
규칙
- 노드의 자료수가 N이면, 자식 수는 N+1이어야 함
- 각 노드의 자료는 정렬된 상태여야함
- 루트 노드는 적어도 2개 이상의 자식을 가져야함
- 루트 노드를 제외한 모든 노드는 적어도 M/2개의 자료를 가지고 있어야함
- 외부 노드로 가는 경로의 길이는 모두 같음.
- 입력 자료는 중복 될 수 없음
B+ Tree
데이터의 빠른 접근을 위한 인덱스 역할만 하는 비단말 노드(not Leaf)가 추가로 있음
(기존의 B-Tree와 데이터의 연결리스트로 구현된 색인구조)
B-Tree의 변형 구조로, index 부분과 leaf 노드로 구성된 순차 데이터 부분으로 이루어진다. 인덱스 부분의 key 값은 leaf에 있는 key 값을 직접 찾아가는데 사용함.
-
장점
-
블럭 사이즈를 더 많이 이용할 수 있음 (key 값에 대한 하드디스크 액세스 주소가 없기 때문)
-
leaf 노드끼리 연결 리스트로 연결되어 있어서 범위 탐색에 매우 유리함
-
-
단점
- B-tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+tree는 무조건 leaf 노드까지 내려가봐야 함
B-Tree & B+ Tree
B-tree는 각 노드에 데이터가 저장됨
B+tree는 index 노드와 leaf 노드로 분리되어 저장됨
(또한, leaf 노드는 서로 연결되어 있어서 임의접근이나 순차접근 모두 성능이 우수함)
B-tree는 각 노드에서 key와 data 모두 들어갈 수 있고, data는 disk block으로 포인터가 될 수 있음
B+tree는 각 노드에서 key만 들어감. 따라서 data는 모두 leaf 노드에만 존재
B+tree는 add와 delete가 모두 leaf 노드에서만 이루어짐